Joshua Thomas Smith
CSCI 496: Senior Portfolio
In partial fulfillment of the requirements for the degree of Bachelor of Technology in Computer-Science (class of 2021)
View My Resume
Reflection Questions
Scripting Project Compilation
- Class: CSCI-315
- Grade: 75% (Fixed Errors Based on Feedback)
- Language(s): C++
- Source Code Repository: Data Structures Portfolio Project
(Please email me to request access.)
Project description
This projects contains two different implementations of a balanced binary search tree data structure. The purpose of the project was to experiment with different techniques of this task, and how the differ in efficiency. This project choose to focus on the AVL tree and Splay tree implementations in particular. This is a full scale implementation, with the ability to add to, delete, find the height of the tree and etc. For in depth examination of the differences read Implementation Differnces.txt. There is a timing program inlcuded to track the speed of actions on the data structures in the src folder. However, you would need to pipe the results into a plotting program (such as gnuplot, that was used for the figure below).
How to compiles / run the programs
Note: There are obj files if you want to run this off linux, but you’d have to use g++ to compile. However, if you have a windows machine the github exe release is much easier to run on windows.
- Download the exectuable from the github release.
- Then run the exectuable to see the example AVL tree, and the program will demonstrate critical methods of the implementation.
If you want to run Splay tree, either contact me or do this to the source files:
- Go to this website https://www.onlinegdb.com/online_c++_compiler#
- import the files that you want to run. For Splay you’d import main, Splaybinarytree.hpp and Splaybinarytree.cpp
- Change main to include the correct tree your running. For example, instead of #include “AVLbinarytree.hpp” it’d be #include “SplaybinaryTree.hpp”
- Click execute, and the main included will run a couple of basic functions to test the implementations.
Image Examples
Figure 1 is a timing chart of the time it takes to add to a tree, and rebalance to maintain order in the tree. In this example both trees preformed about the same in terms of speed before 4500 add operations. However, after this point AVL began to outpreform Splay overall. Especially near the end, Splay spiked to high levels. Meanwhile AVL maintained its constant stable rise with the increasing data sizes. Figure 2 demonstrates a few critical functions that you need to operate a binary tree, and the results they have on the tree structure itself.
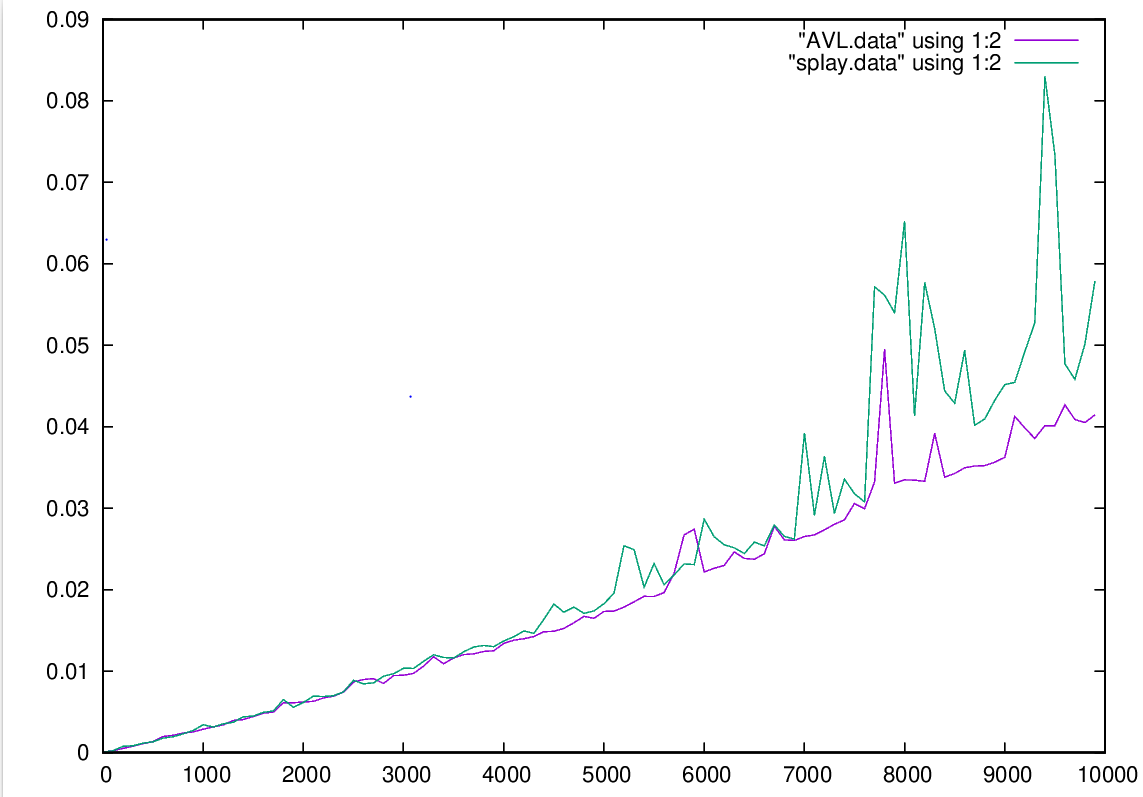
Fig 1. Chart of the Timing for the different implementations. AVL Tree vs. Splay Tree add operations
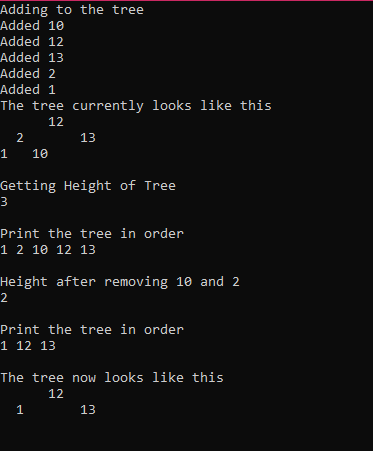
Fig 2. AVL executable showing methods for add, delete, show in order, and how the tree balances.
3. Additional Considerations
Sometimes we have to consider not only the speed of operations with different implementations, but the time it takes to setup the data structure. AVL may have preformed better in speed with larger data sets, but Splay was much easier to implement. In a bussiness setting where a speed of implementation is a priority, Splay would be a serious contender.
For more in depth comparsion see Implementations Differences file.
For more technical details see README.md file.